This is part 3 of the Kafka series.
- Part 1: Introduction to Kafka TCP Fragmentation
- Part 2: Introduction to Reactor Pattern and Kafka’s Reactor Implementation
The source code referenced in this article uses Kafka’s trunk branch. I’ve pushed it to my personal repo for version alignment with this article:
https://github.com/cyrilwongmy/kafka-src-reading
In this part, we will briefly introduce the Kafka’s message protocol. Kafka’s server and client communicate through a custom message protocol. By understanding how Kafka’s RPC protocol is implemented, we can apply similar principles when designing our own protocols.
Introduction
HTTP 1.x and gRPC are convenient, but too heavyweight for a high‑throughput, low‑latency durable log. Each HTTP header on a TCP frame adds unnecessary bytes to every message. Even Protobuf’s var‑int encoding becomes a bottleneck when allocating thousands of objects per millisecond, putting strain on heap memory and garbage collection.
The Apache community’s “don’t break users” philosophy requires brokers and clients to communicate across major versions. Their solution: a custom protocol with tagged fields that allows new data to be appended to message ends. Like HTTP/2 frames, older clients can safely ignore unknown tags.
Serialization and Deserialization Mechanisms
At their core, all application-layer protocols—whether it’s RPC or HTTP—follow a similar idea: converting in-memory objects into binary form for network transmission. On the receiving end, the system reads this binary stream and reconstructs the original in-memory structures by parsing it piece by piece.
Kafka Protocol Request Structure
All request types in Kafka are located under the org.apache.kafka.common.requests package. Let’s use ProduceRequest as an example to walk through its protocol implementation.
Anatomy of ProduceRequest
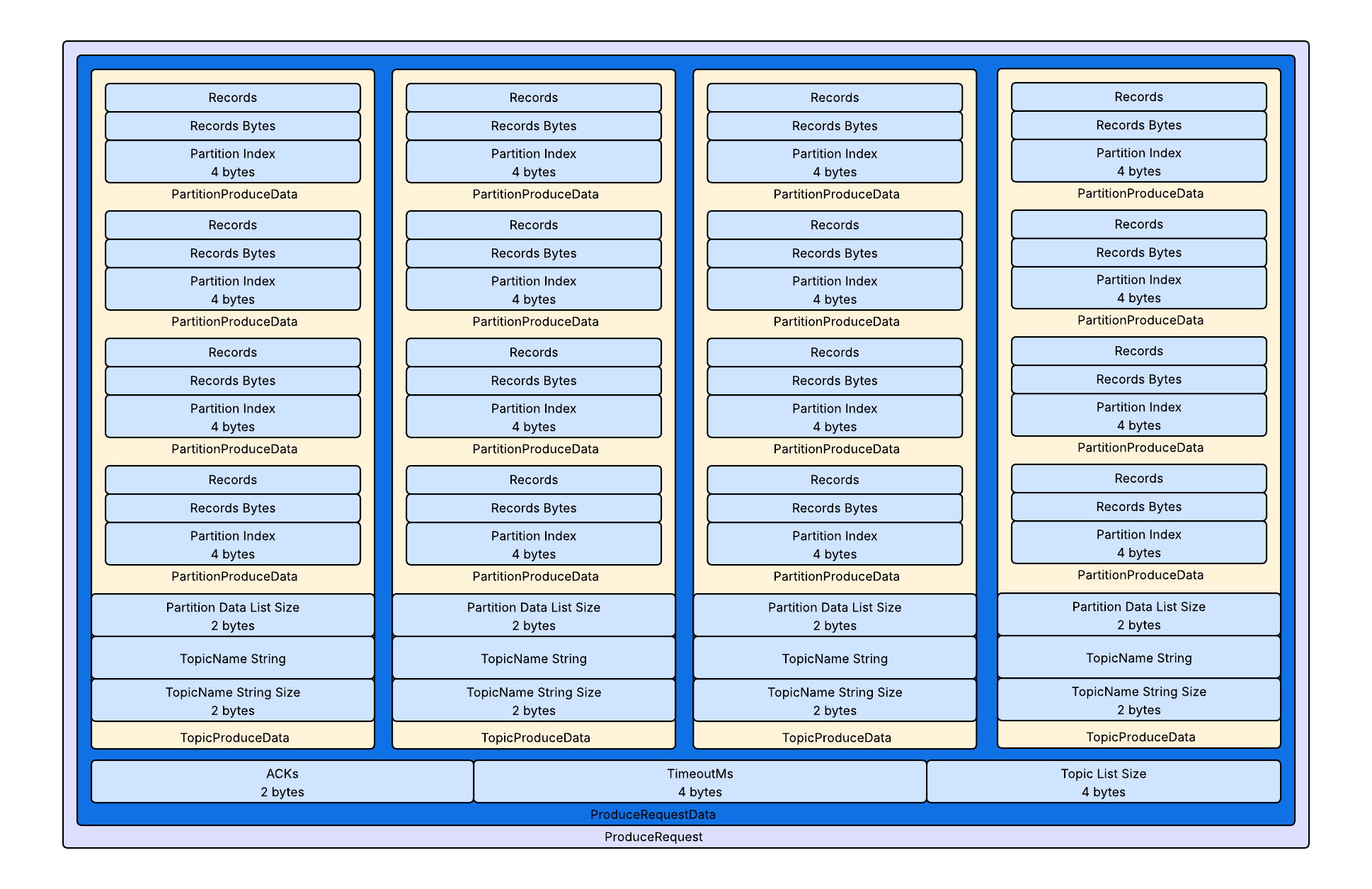
To understand the protocol, we’ll look at a simplified version for clarity. As shown in the diagram, the network representation of a ProduceRequest is a deeply nested object structure—much like the layered model in computer networking.
| Level | Field | Type | Meaning | Example |
|---|---|---|---|---|
| 0 | acks |
INT16 | Required replica acknowledgements | ‑1 (all ISRs) |
| 0 | timeoutMs |
INT32 | Hard write timeout (ms) | 30000 |
| 0 | topicData.length |
INT32 | Number of TopicProduceData |
2 |
| 1 | name |
STRING | Topic name | "orders" |
| 1 | partitionData.length |
INT32 | Number of PartitionProduceData |
3 |
| 2 | index |
INT32 | Partition index | 0 |
| 2 | recordSetSize |
INT32 | Size of the record set (bytes) | 1024 |
| 2 | recordSet |
BYTES | Compressed batch of messages | … |
- The outermost object is ProduceRequestData, which contains configuration info and the number of topic entries.
- Why record the number of topics? Because the receiver must know how many TopicProduceData entries to expect—otherwise, it can’t determine message boundaries. For unknown-length sequences, you must explicitly record the size, typically using 2 or 4 bytes. The receiver reads those bytes and converts them into int or short to know how many elements to parse next.
- A single ProduceRequest can target multiple topics, each represented by a TopicProduceData object.
- Each TopicProduceData includes:
- the byte length and content of the topic name,
- the number of partitions,
- and a list of PartitionProduceData.
Each PartitionProduceData records:
- the partition index,
- the length of the record batch,
- and the actual set of messages.
Kafka’s Serialization Implementation
Kafka uses code generation to implement serialization and deserialization. This helps avoid typos and ensures compatibility across protocol versions. A global ObjectSerializationCache is used to cache UTF-8 encoded strings and avoid recomputation.
When serializing a ProduceRequest, Kafka calls the write method from ProduceRequestData, which implements the Message interface. This method serializes the in-memory object into a Writable—usually a wrapper around Java NIO’s ByteBuffer, like ByteBufferAccessor.
The write method contains many version checks to ensure forward/backward compatibility, which is critical when designing a robust protocol.
Key fields written during serialization:
- acks: how many replicas must confirm the write.
- timeoutMs: how long the broker should wait for replicas to acknowledge.
- topicData.size(): number of topics in the list (not byte length).
- Each topic’s data is serialized via its own write method.
Why Length Fields Matter? In OSI Layer 4, TCP guarantees byte‑stream ordering but not message boundaries. This means that without explicit size indicators, a receiver cannot determine where one logical request ends and another begins. As a result, every ARRAY / STRING / BYTES field in ProduceRequest follows a length → payload structure.
Here’s a simplified version of the write method from TopicProduceData:
public void write(Writable writable, ObjectSerializationCache cache, short version) {
byte[] stringBytes = cache.getSerializedValue(name);
if (version >= 9) {
writable.writeUnsignedVarint(stringBytes.length + 1);
} else {
writable.writeShort((short) stringBytes.length);
}
writable.writeByteArray(stringBytes);
if (version >= 9) {
writable.writeUnsignedVarint(partitionData.size() + 1);
} else {
writable.writeInt(partitionData.size());
}
for (PartitionProduceData p : partitionData) {
p.write(writable, cache, version);
}
}
This recursive structure ensures that all nested fields are serialized correctly. Ultimately, all data ends up in a ByteBuffer, which Kafka sends over the network.
Optimization: Zero-Copy
For high-performance messaging, Kafka avoids loading entire files into memory before sending. It uses zero-copy techniques to minimize unnecessary memory copies.
The usual data flow from disk to network is:
Disk -> Kernel Space -> User Space -> Socket Buffer -> Network
Kafka uses zero-copy to avoid the memory copy from the kernel space to the user space:
Disk -> Kernel Space -> Network
We’ll dive deeper into this in a future blog about Kafka’s zero-copy optimizations.
Kafka’s Deserialization Implementation
Deserialization is handled by the read method in the Message interface, which reads from a Readable (usually a buffer).
Here’s how ProduceRequestData.read() works:
- Read 2 bytes → convert to short for acks
- Read 4 bytes → convert to int for timeoutMs
- Read 4 bytes → get number of TopicProduceData entries
- For each topic, invoke its read method to deserialize nested structures
Example:
public void read(Readable readable, short version) {
this.acks = readable.readShort();
this.timeoutMs = readable.readInt();
int arrayLength = readable.readInt();
TopicProduceDataCollection collection = new TopicProduceDataCollection(arrayLength);
for (int i = 0; i < arrayLength; i++) {
collection.add(new TopicProduceData(readable, version));
}
this.topicData = collection;
}
This is essentially the reverse of the write method.
Takeway about forward/backward compatibility
| Scenario | Strategy | Benefit |
|---|---|---|
| Add a field | Append to tail or use a tagged field | Old clients ignore it |
| Remove field | Markdeprecated, keep parser | Old data can still replay |
| Widen field | Dual‑write / dual‑read, then retire old | Online upgrades stay safe |
Conclusion
Implementing a simple RPC-like protocol is quite approachable. From Kafka’s design, we learn how to use recursive serialization/deserialization effectively.
For further optimization, consider:
- Compressing data to reduce transmission size,
- Reducing memory copies when transmitting from disk or in-memory buffers to the network (e.g., using zero-copy).
These principles form a solid foundation for building efficient and maintainable binary protocols.
If you have any question, free feel to leave issues at this repo.