This is part 2 of the Kafka series. In this part, we will dive into the Reactor pattern and how Kafka implements it. In the next following series, we will dive into each component of the Reactor pattern.
The source code referenced in this article uses Kafka’s trunk branch. I’ve pushed it to my personal repo for version alignment with this article:
https://github.com/cyrilwongmy/kafka-src-reading
What is the Reactor Pattern?
(Readers familiar with the Reactor pattern can skip to the Kafka’s Reactor Implementation section)
Understanding the Reactor pattern requires starting with the evolution of fundamental network I/O models: from blocking I/O to multithreading and pooling techniques, then to non-blocking I/O, culminating in the Reactor pattern.
Blocking I/O, Non-blocking I/O, and Asynchronous I/O (AIO)
To discuss Reactor, we begin with the basic TCP network I/O processing flow. Programming languages typically provide a Socket API. First, create a listening Socket (serverSocket), bind it to a port, and listen. Then call the accept method to block and wait for client connections. When accept returns, you obtain a unique Socket (connectionSocket) representing that connection. Next, call read and write on this connectionSocket for data transfer.
# Server socket listening for incoming connections
serverSocket = Socket()
serverSocket.bind(port, server_ip)
connectionSocket = serverSocket.accept() # Blocks until a client connects
# Read and write with the connected client
connectionSocket.read(buffer) # Blocks reading data from network into buffer
connectionSocket.write(buffer) # Blocks writing data from buffer to network
As shown above, read and write are blocking system calls. Program execution halts (blocks) at the read line until:
- The client sends data.
- Data is read from the NIC into the kernel buffer.
- Data is copied from the kernel buffer to the program’s user-space buffer (
buffer).
This means the thread cannot perform other tasks while blocked. Ideally, the thread could handle other tasks while waiting for steps 1 and 2 (especially time-consuming), returning only when the data is ready in user space. This is the goal of Asynchronous I/O (AIO).
In Linux 5.1+ kernels, io_uring provides truly asynchronous read/write supporting all steps 1-3. However, io_uring’s shared memory approach for high performance introduces potential security considerations.
Prior to io_uring, Linux’s AIO support was mostly simulated in user space with limitations (e.g., inadequate buffered I/O support). The more traditional approach for high-performance servers is NIO (Non-blocking I/O). While the OS handles steps 1-2 (data arriving in the kernel), and non-blocking Socket calls ensure read/write don’t block themselves, the user thread still needs to poll or wait for event notifications (like epoll) to know when data is ready in user space (step 3). Kafka achieves its high throughput using NIO (specifically epoll).
After optimizing the blocking issues with read/write, a single thread’s network I/O efficiency improves significantly as it can utilize the CPU more fully.
The pseudo-code above shows a simple model. To handle many concurrent clients, each connection requires its own thread/process. After the main thread **accept**s a connection, it hands the connectionSocket to a dedicated worker thread, which executes the read and write logic.
Multithreaded I/O and Pooling
The C10K problem (10,000 concurrent connections per machine) is common in modern internet systems. Creating one thread per client connection would cause server threads to surge (potentially tens of thousands), while modern CPUs typically have only dozens of cores (including hyper-threading). Excessive threads lead to frequent context switches and CPU cache thrashing, severely degrading performance.
Using Pooling, we create a fixed-size thread pool. The main thread only **accept**s connections and hands the connectionSocket to a worker thread in the pool for read/write operations. This prevents unbounded thread creation and limits resource consumption.
Reactor Pattern
The Reactor pattern has several variants, with flexible combinations of Acceptor, Processor (or SubReactor), and Handler roles.
We focus on the form similar to Kafka’s design:
- Main Reactor: Typically single-threaded. Listens for connection request events (
accept) and dispatches new connections to the Acceptor. - Acceptor: Completes the actual connection establishment (
acceptreturnsconnectionSocket) and registers the connection with a SubReactor. - SubReactor: Usually multiple instances (each bound to a
Selector/epoll). Monitors read/write events (read,write) on established connections. Upon detecting events, it delegates I/O tasks to Handlers. - Handler: Worker threads in a pool. Execute actual business logic (e.g., computation, disk I/O, or other time-consuming operations).
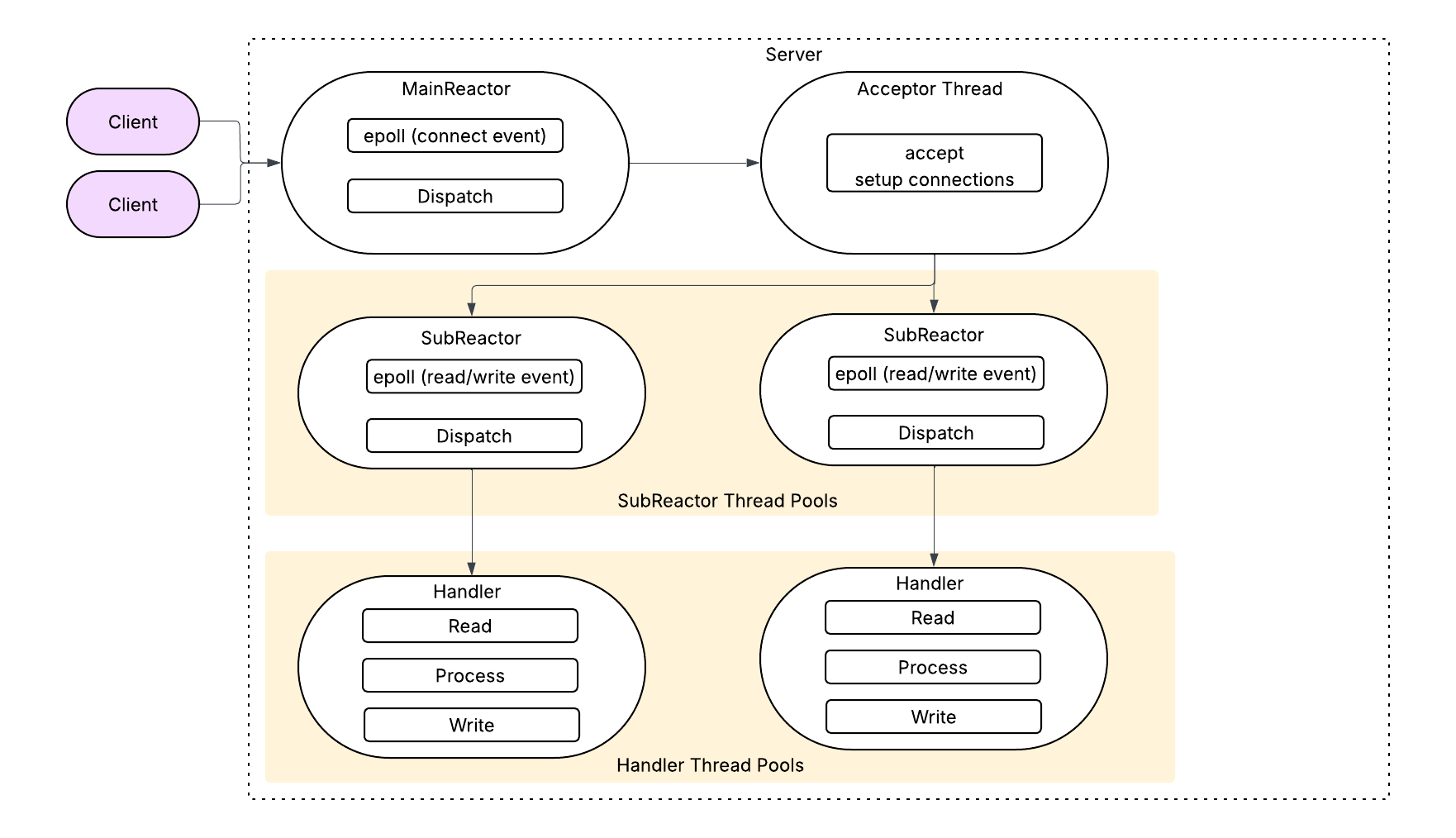
The MainReactor and SubReactor only focus on rapid event dispatch (hence “Reactor”). They do not handle business logic.
The MainReactor handles only connection events, making it extremely efficient. Time-consuming tasks (connection setup, I/O) are delegated to the Acceptor, SubReactors, and Handlers. Components communicate via task queues (e.g., MainReactor queues new connections, Acceptor consumes the queue), decoupling them, smoothing traffic bursts, and enhancing load capacity.
Depending on application needs, designs can have M Reactors and N Handlers. The Reactor pattern is highly flexible. For example, Redis uses a single Reactor with a single-threaded Handler because its primary operations are in-memory reads/writes with no CPU-intensive tasks—bottlenecks are mainly network I/O. Handlers and Reactors can even be separate processes, though this involves complex IPC.
Proactor Pattern
The Proactor pattern builds upon truly asynchronous I/O (AIO). It aims to eliminate the Reactor’s limitation where user threads still wait for data copying (step 3), pursuing ultimate performance. It can be seen as an enhanced Reactor: Handlers submit I/O operations (e.g., read/write) to the kernel. After the kernel completes all steps (including data copying), it proactively notifies the user thread that “data is ready in the user buffer,” allowing immediate processing. Future articles will compare NIO and AIO performance.
Kafka’s Reactor Implementation
A full implementation analysis would be lengthy. This section focuses on how Kafka’s request processing flow embodies the Reactor pattern.
Kafka employs a single Acceptor (Main Reactor) + multiple Processors (SubReactors) + multiple Handlers structure.
Core Components and Flow
- Acceptor (Main Reactor): Uses a
Selector(epoll) to listen for connection events (OP_ACCEPT). Accepts new connections and distributes them to Processors. - Processor (SubReactor): Each Processor has its own
Selector(epoll). Monitors read/write events (OP_READ,OP_WRITE) on registered connections, performing network I/O (receiving requests, sending responses). - RequestChannel (Task Queue): A
BlockingQueue. Processors place parsed requests into this queue; Handlers consume requests from it. Decouples Processors and Handlers, providing buffering and load leveling. - KafkaRequestHandler (Handler): Worker thread pool. Executes business logic (processes requests, generates responses).
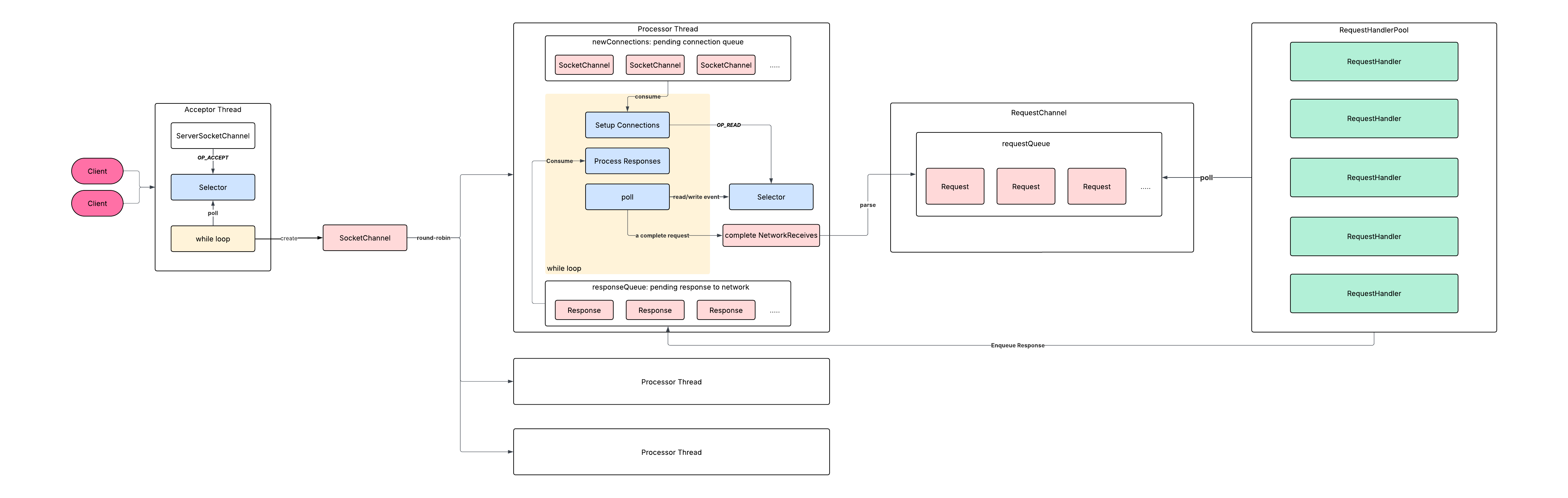
Acceptor
The Acceptor class extends Java’s Thread. Upon startup (start()), it creates the server listening SocketChannel (serverChannel), starts all Processor threads, then starts its own thread (run()).
def start(): Unit = synchronized {
// ... (details omitted for clarity)
serverChannel = openServerSocket(endPoint.host, endPoint.port, listenBacklogSize)
processors.foreach(_.start()) // Start all Processor threads
thread.start() // Start the Acceptor thread itself (calls run())
started.set(true)
}
The run() method core is a loop: register serverChannel for OP_ACCEPT events with the Selector, then repeatedly call acceptNewConnections(). A key design is catching all Throwable to prevent thread death and service disruption.
/**
* Accept loop that checks for new connection attempts
*/
override def run(): Unit = {
serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)
try {
while (shouldRun.get()) {
try {
acceptNewConnections()
closeThrottledConnections()
} catch {
// Catch all throwables to prevent thread exit on exceptions (e.g., bad request, channel issue).
// Ensures broker keeps serving other clients.
case e: ControlThrowable => throw e
case e: Throwable => error("Error occurred", e)
}
}
} finally {
closeAll()
}
}
acceptNewConnections() is the core logic: Use selector.select() to detect OP_ACCEPT events. For each ready SelectionKey, call accept() to get the client SocketChannel. Then, using a round-robin strategy, assign this SocketChannel to a Processor (via assignNewConnection(socketChannel, processor), placing it in the Processor’s newConnections queue).
/**
* Listen for new connections and assign accepted connections to processors using round-robin.
*/
private def acceptNewConnections(): Unit = {
val ready = nioSelector.select(500)
if (ready > 0) {
val keys = nioSelector.selectedKeys()
val iter = keys.iterator()
while (iter.hasNext && shouldRun.get()) {
try {
val key = iter.next
iter.remove()
if (key.isAcceptable) {
accept(key).foreach { socketChannel =>
// Assign the channel to the next processor (using round-robin) to which the
// channel can be added without blocking. If newConnections queue is full on
// all processors, block until the last one is able to accept a connection.
var retriesLeft = synchronized(processors.length)
var processor: Processor = null
do {
retriesLeft -= 1
processor = synchronized {
// adjust the index (if necessary) and retrieve the processor atomically for
// correct behaviour in case the number of processors is reduced dynamically
currentProcessorIndex = currentProcessorIndex % processors.length
processors(currentProcessorIndex)
}
currentProcessorIndex += 1
} while (!assignNewConnection(socketChannel, processor, retriesLeft == 0))
}
} else
throw new IllegalStateException("Unrecognized key state for acceptor thread.")
} catch {
case e: Throwable => error("Error while accepting connection", e)
}
}
}
}
Processor
Processor is also a thread (Thread). Its start() method launches the thread (run()).
def start(): Unit = {
if (!started.getAndSet(true)) {
thread.start()
}
}
The run() method is the processing core, containing a main loop with key steps:
override def run(): Unit = {
try {
while (shouldRun.get()) {
try {
configureNewConnections() // Setup new connections queued by Acceptor
processNewResponses() // Prepare responses for sending
poll() // Perform network I/O (epoll)
processCompletedReceives() // Handle received requests
processCompletedSends() // Handle completed sends
processDisconnected() // Handle disconnected clients
closeExcessConnections() // Enforce connection quotas
} catch {
// Catch all throwables to keep the processor thread running.
case e: Throwable => processException("Processor got uncaught exception.", e)
}
}
} finally {
debug(s"Closing selector - processor $id")
CoreUtils.swallow(closeAll(), this, Level.ERROR)
}
}
configureNewConnections
Takes **SocketChannel**s from the newConnections queue (populated by Acceptor) and registers them with the Processor’s own dedicated Selector, initially listening only for OP_READ events.
private def configureNewConnections(): Unit = {
var connectionsProcessed = 0
while (connectionsProcessed < connectionQueueSize && !newConnections.isEmpty) {
val channel = newConnections.poll()
try {
debug(s"Processor $id listening to new connection from ${channel.socket.getRemoteSocketAddress}")
selector.register(connectionId(channel.socket), channel) // Register with Processor's own Selector (for OP_READ)
connectionsProcessed += 1
} catch {
case e: Throwable =>
val remoteAddress = channel.socket.getRemoteSocketAddress
connectionQuotas.closeChannel(this, listenerName, channel) // Cleanup on error
processException(s"Processor $id closed connection from $remoteAddress", e)
}
}
}
processNewResponses
Processes responses to be sent. Each Processor has a dedicated response queue (responseQueue). After processing a request, Handlers place the response into the corresponding Processor’s responseQueue. This method:
- Checks if the associated Channel is closed.
- Converts the
Responseinto a network-ready packet (NetworkSend) and associates it with the Channel. - Registers
OP_WRITEevents for the Channel (if not already registered). - (Note: Kafka uses a
mute/unmutemechanism to manage per-Channel event registration, ensuring a Channel never has multiple in-flight requests/responses. Details covered later).
poll
Core network I/O operation. Calls Selector.poll(pollTimeout) (performing epoll_wait), handling all ready OP_READ and OP_WRITE events:
-
OP_READ: Reads data, handles TCP packet coalescing/splitting, assembles full requests. -
OP_WRITE: Sends theNetworkSenddata associated with the Channel.(Complex internals involving
Selectorimplementation,NetworkReceive/NetworkSend,mute, etc., are covered in subsequent articles).
processCompletedReceives / processCompletedSends
processCompletedReceives handles fully assembled requests (NetworkReceive) from the poll() phase:
- Parses
NetworkReceiveinto a Kafka protocolRequestobject. - Places the
Requestinto theRequestChannelqueue for Handler processing.
processCompletedSends handles successfully sent responses (NetworkSend) from the poll() phase:
- Performs cleanup (e.g., releases
ByteBuffer). - Unmutes the Channel (calls
unmute()) to allow it to listen forOP_READevents again (related tomutemechanism).
RequestChannel
Acts as the task queue between Processors and Handlers. Core is a BlockingQueue.
class RequestChannel(val queueSize: Int, ...) {
import RequestChannel._
private val requestQueue = new ArrayBlockingQueue[BaseRequest](queueSize) // Core Blocking Queue
// ... (other fields and methods)
}
- Processor (Producer): Calls
RequestChannel.sendRequest(request)to enqueue parsed requests. - Handler (Consumer): Calls
RequestChannel.receiveRequest(timeout)to dequeue requests for processing.
KafkaRequestHandler
Threads in the worker thread pool (KafkaRequestHandlerPool). Their run() method loops to get requests from the RequestChannel (receiveRequest) and dispatches them to KafkaApis.handle(request).
override def run(): Unit = {
// ... loop ...
val req = requestChannel.receiveRequest() // Get request from queue
apis.handle(req, requestLocal) // Dispatch to KafkaApis for processing
// ...
}
KafkaApis.handle() is the entry point to Kafka’s business logic. It routes requests based on type (ApiKeys) to specific handlers (e.g., handleProduceRequest, handleFetchRequest).
/**
* Top-level method that handles all requests and multiplexes to the right api
*/
override def handle(request: RequestChannel.Request, requestLocal: RequestLocal): Unit = {
try {
trace(s"Handling request:${request.requestDesc(true)} from connection ${request.context.connectionId};...")
if (!apiVersionManager.isApiEnabled(request.header.apiKey, request.header.apiVersion)) {
throw new IllegalStateException(s"API ${request.header.apiKey} with version ${request.header.apiVersion} is not enabled")
}
request.header.apiKey match { // Dispatch based on request type
case ApiKeys.PRODUCE => handleProduceRequest(request, requestLocal)
case ApiKeys.FETCH => handleFetchRequest(request)
case ApiKeys.LIST_OFFSETS => handleListOffsetRequest(request)
case ApiKeys.METADATA => handleTopicMetadataRequest(request)
case ApiKeys.OFFSET_COMMIT => handleOffsetCommitRequest(request, requestLocal)
// ... (handlers for all other API keys) ...
case ApiKeys.API_VERSIONS => handleApiVersionsRequest(request)
}
} catch {
case e: Throwable => requestHelper.handleError(request, e) // Handle processing errors
}
}
After processing, the Handler constructs a Response and sends it back to the corresponding Processor via RequestChannel.sendResponse() (using the associated response queue). The Processor then sends it to the client.
Summary
This article dissected how Kafka leverages the Reactor pattern (Single Acceptor + Multiple Processors + RequestChannel Queue + Handler Thread Pool) to achieve high-throughput network processing:
- Acceptor efficiently accepts and distributes new connections.
- Processor uses NIO (
epoll) to efficiently handle I/O events for many connections (I/O-bound). - RequestChannel decouples network I/O (Processor) from business processing (Handler), buffering requests.
- Handler thread pool focuses on business logic (CPU/disk-bound).
This architecture effectively isolates different task stages, maximizes multi-core CPU utilization, and smooths traffic fluctuations via queue buffering, forming the foundation of Kafka’s high throughput and concurrency.
We focused on the request flow mapping to the Reactor pattern, omitting details like network I/O (packet handling, Selector internals, mute mechanism), request parsing, and Handler internals. These will be explored in future articles.
If you have any question, free feel to leave issues at this repo.